From 孫利民 尚誌(zhì)強
原載(zǎi)於《橋梁》雜誌2018年第4期(qī)
結構健康監測技術被(bèi)廣(guǎng)泛(fàn)應用於(yú)大(dà)型橋(qiáo)梁(liáng)的養護管理,但受數據分析方法和計算方式的限製,橋梁結(jié)構健康監測係統(tǒng)所積累的海量監測數據並未得到有(yǒu)效利用。近幾年,大數(shù)據技術的發展為橋梁結構健康監(jiān)測數據的有效利用帶來(lái)了希望。大(dà)數據可視化分析是大數據分析的一個分支,能夠實現高維數據可視化(huà)的同時,識別數據中的模式。
在傳統的橋梁養(yǎng)護管理中,基於人工檢(jiǎn)測(cè)的結構狀態評估扮演了(le)重要角色,然而人工檢測工作量大、主觀性強,難以實現對結構性能的長期(qī)定量跟蹤。近年來,結構健康監測技(jì)術(Structural Health Monitoring, SHM)在大跨橋梁的養護管理中得到廣泛應用。橋梁結構健康監測通過在結構上安裝傳感器,以實時獲取橋址環境(jìng)和結構響應的信息(xī),並基於這些信息對橋梁的技術狀態做出實時、自動的評估甚(shèn)至安全預(yù)警。我國當前至少(shǎo)有240多座大跨度橋梁安裝了結構健康監測係統(Structural Health Monitoring System, SHMS),經過長期的觀測,這些監(jiān)測(cè)係統積累了大量的數據,基於這些(xiē)數據有(yǒu)效解讀結構的狀態、識別可能的損傷,成為目前SHM研究的關鍵問題。
利用SHM數據進行結構狀態評估和損傷識別有“基於(yú)模型”和“數據驅動”兩類方法。基(jī)於模型的方法(fǎ)本質上是橋(qiáo)梁結構有限元建(jiàn)模、模型修正(zhèng)、係統參數反演的過程,對(duì)理論模型的精度和監測數據的質量有(yǒu)很高的要求,目前在實際工(gōng)程中應用效果還不理想。數據驅動的方法關注監測所得到的輸入和輸出數據相(xiàng)關關係的(de)變(biàn)化規律,以識別結(jié)構狀(zhuàng)態所對應的模式,借助於成熟的統計學理論,數據驅(qū)動方法在SHM中得到廣泛應用。但傳統的統計方法由於計算能力和分析手段的限製,隻能分析少部分、低維度的數據樣本,且無法高效地(dì)呈現分(fèn)析結果,因此尚不足(zú)以解決海量、高維SHM數據的分析問題。
大數據技術(shù)是近幾年的新興技(jì)術,已在互聯網、電子商務、醫學(xué)等領域得到廣泛應(yīng)用,改善了計算能力不足、數據分析方法低效(xiào)等問題,在SHM的數據處理上(shàng)也展現出廣闊的應用前景。大數據可視化分析是大數據分析(xī)的(de)一個重要(yào)分支,該(gāi)方法將人所具備的、機器並不擅長的認知能力(lì)融入到分析過程中,可提升數據(jù)分析的效率和準確性,並可對高維數據進行(háng)直觀的(de)呈現。
“大數據(jù)”概念首(shǒu)次提出於1996年,2008年《Nature》雜誌推出大數據專欄,2011年麥肯錫公司的(de)研究報告對大數據的(de)關鍵技術和應(yīng)用領域等進行了全麵的分析(xī)總結,大數據(jù)逐漸(jiàn)為各行各業所關注。“大數據”的內涵和(hé)外延在不斷地被豐富,在(zài)不同(tóng)的文獻中,“大數據”被描述為數據集、可實現的功能(néng)、數據變現過(guò)程、架構和(hé)技術等。大數據應該從數據集特征、思維方式、技(jì)術三個方麵進行理解(圖1)。
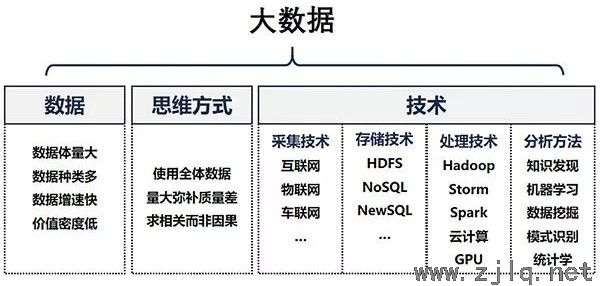

一般認為,大(dà)數據具備4V特征,即數據體量大(Volume)、種(zhǒng)類多(Variety)、增速快(Velocity)、價值(zhí)密度低(Value)。4V特(tè)征並沒有明確地限定大數據(jù)的體量(liàng)規模,因而可廣泛適用於各個行業。
大數據分析應具備的三個思維方式,即“使用全體數據進行(háng)分析”“接受數據混雜性,數據量大彌補質量差”“追求相關關係而非因果關係”。因而具有以(yǐ)下(xià)特點(diǎn):與傳統統計分析隻使用一小部分隨機抽樣數據相比,使用(yòng)全體數據可(kě)以發現更多的細節和有價值的信息(xī);接受數據混雜、增大數據量能夠簡化分析模型並避免過擬合,從而獲得(dé)更準確的分析結果;從相關關係(xì)切入則可為數據分析提供(gòng)新的(de)視角(jiǎo)。當前大數據處理技術已使得分析所(suǒ)有數據成為可能,通過大數據分析挖掘相關關係(xì)也取得了許多成功應用;但以數據量大彌補質量(liàng)差時,如果(guǒ)全部數據中的噪聲多於信號(hào)則(zé)信號(hào)易被(bèi)掩蓋(gài),因(yīn)此不能(néng)盲目收入所有數據(jù),仍需尋找與分析目的強相關的數據。
大數據的技術主要體現在數據采集(jí)、存儲、計算處理、分析方法等幾(jǐ)個方麵。大數據的(de)采集、存儲、計算等多以軟件工具的方式呈現,如用於獲取數據的物(wù)聯網、互聯網(wǎng),用以存儲數據的Hadoop分布(bù)式文件係統、NoSQL數據庫,用於數據計算的Hadoop生態圈、MapReduce、Spark、Storm、雲計算等。大數據分析方法涵蓋以各種術語所表示的(de)數據分析方法,包括數據(jù)庫知識(shí)發現(KDD)、數據挖掘、機器學(xué)習、模式識別、統計學等。這些術語雖(suī)然在應用領域和關注點上有所不同,但當前(qián)在大(dà)數據語境下,其間(jiān)的差別可不必考(kǎo)究(jiū)。
與大數據(jù)分析方法有關的(de)另一個術語是人工智能,它是一個宏大的概念,它的提(tí)出遠早於大(dà)數據。人工智能與大數據分析的主要區別(bié)是目(mù)標上的不同,前者(zhě)是產生具有智能行(háng)為的東(dōng)西(xī),後者則用以發現數據中隱藏的知識。但二者都要靠大數據實體的支撐實現,且(qiě)可以共用(yòng)分析方法。當前人工智(zhì)能的代表技術是(shì)深(shēn)度學習,屬於機器學習的一個子集,由於在圖片、語音(yīn)等識別問題中的出色性能,常脫離(lí)於機器學習被突出強調。
KDD、數據挖掘等同於機器學習,貫(guàn)穿於大數據分析(xī)的整個流程,模式識別是其中的一個環節。大數據分析流程(chéng)在KDD流程的基礎上得到完善,強調了多(duō)源異(yì)構數據融合和特征提取的重要(yào)性,最終可由數據預處理、數據融合、特(tè)征工程、模式識別、可視化等環節構成。但應該注意到,這幾個步驟之間的順序並非絕對的(de)一成不變,且有可能在某一步實(shí)現多個功能。
數據可視化在大數據分析流程中的功能是呈現數據分析的結果,當被直接用於探索數據、挖掘數據中的模式時也被(bèi)稱為大數據可視化分析。大數據(jù)的一個特征是數(shù)據(jù)種類多(duō),在數(shù)據(jù)集中表現為數據的維度高。高維數據難以有效地可視化(huà),且會引起數據分(fèn)析中的維度災難問題,即數據集在(zài)高維空間中分布(bù)稀疏,缺乏足夠的數據構建模型。傳統數據(jù)分析常以降維的方式減少(shǎo)數(shù)據(jù)集(jí)中的變(biàn)量數,由此也會帶來原始數據集中信(xìn)息量(liàng)的減少。大數據可視化分析為有效地呈現、分析高維數據提供了新的思路,在SHM的模(mó)式識別問題中(zhōng)也展現出應用的潛力。
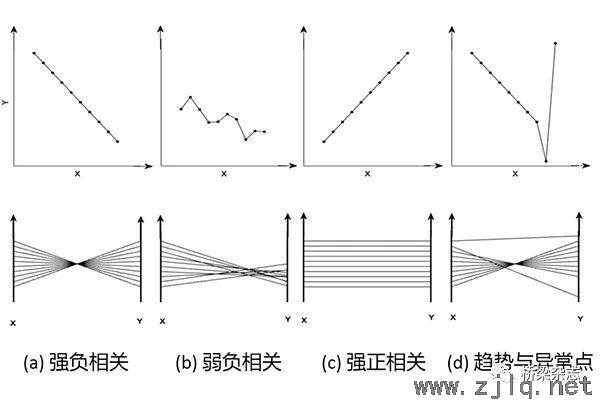
平行坐標圖(tú)法(parallel coordinate plot, PCP)、t分布隨機鄰域嵌入法(t-SNE)是當前高維數據可視化中常(cháng)用的兩種方法(fǎ)。t-SNE在高(gāo)維空間中構建每個數據(jù)點對(duì)其近鄰的概率分布,並在低維空間中重構該概率分布,通過最小化兩個概率分布間的差距,以保證高維空間中的數據點(diǎn)在低維空間中具有相近的局(jú)部結構,最終將結果顯(xiǎn)示於(yú)二維或三維坐標圖上。t-SNE雖然能有(yǒu)效探(tàn)知原始數據(jù)的結構和分布(bù),但需要很高的計算開銷。與t-SNE相比,PCP不需要(yào)對原始數據進行降(jiàng)維顯示,且具有更高的可視化效率。PCP通過N個平行坐標軸將N維數據投射到二維空間中,每個數據點(diǎn)被(bèi)表示為PCP中的一(yī)條線段(duàn),由此原始的高維數據集可被表示為一個幾何係統。PCP能夠(gòu)呈現數據間(jiān)的相關關係,因而具有模式(shì)識別功能,這也體現(xiàn)了大數據“追求相關關(guān)係而非因果關係(xì)”的思維方式。PCP的模(mó)式識別功能由(yóu)三個重要的可視化特征實現(xiàn),分別為以下幾方麵——
線段夾角,表明變量間的正負相關關係,圖3(a)中線段交匯於一(yī)點(diǎn),表示兩變量間具有強負相關關係,圖3(c)中線段彼此平行,表示兩個變量間具有強正相(xiàng)關關係。
線段交點區(qū)域,表明變量間相關關係的強弱,圖3(b)線段(duàn)交匯於一個區域,表示兩變量間具有弱負相關關係。
線段分(fèn)布,表明趨勢模式或異常點模(mó)式。趨勢(shì)模式對應密集區域的線段,異常點則是稀疏區域的(de)線段。圖3(d)下方的線段可判斷為趨勢,上方的(de)線段為異常點。
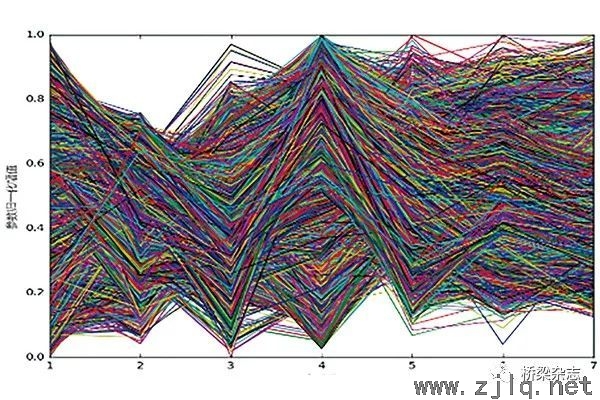
PCP用於大數據集時,線段數量的增多會造成線段間的重疊、遮擋(圖4),從而掩蓋坐標圖中(zhōng)的可視化(huà)特征。為消(xiāo)除線段重疊、減少視覺混雜,學者們提出了各種改進的PCP方(fāng)法。基於Alpha混合的PCP方法(fǎ)較(jiào)早地被提出,其將PCP中的每條線段賦予較低的透明度,使線段稀疏部分的顏色被淡化、線(xiàn)段密集區域的顏色被加深。此種方法的缺(quē)陷是透明度值存在下限,不能擴展到更大規模(mó)的數據(jù)集(jí)中。基於分布(bù)直方圖的PCP方法(圖10)按(àn)每(měi)兩個變量計算二維分布直方圖,以直方圖中的每一格表示坐標圖中的一(yī)條線段(duàn),並按直方圖的頻率值設定線段的透明度。由於能在大幅減少線段數量的同時,保(bǎo)留(liú)PCP中的可視化特征,基於分(fèn)布直方(fāng)圖的方法可被擴展到更大規模的數據集。除此之外(wài),PCP中減少(shǎo)視覺混雜的方法還有基於捆紮的方法、基於聚類的方法(fǎ)、基(jī)於刷的方法等。
橋梁SHM的監測內容主要包(bāo)括環(huán)境(jìng)運營荷載與結構響應兩類,環境與運營荷載的(de)監測項有溫度、降水量、空氣濕度、風荷載、交通荷載、地震輸(shū)入等;結構響應(yīng)監測項有幾(jǐ)何變形(xíng)和位移、加速度、應變、轉角、索力等。基於SHM數據首先(xiān)可(kě)以進行結構損傷(shāng)或異常識別,但(dàn)在實際橋梁中這還很(hěn)難理想實現,一是因為當前國(guó)內安裝有SHMS的大部分橋梁服(fú)役時間較(jiào)短,尚未出現(xiàn)明顯的損(sǔn)傷和退化;二是受傳感技術和(hé)數據分析方法的限製,結構初期的微小損傷難以被識別。進行結構狀態評估是SHM的主(zhǔ)要目的之一,對於服役初期階段尚無明顯損傷的新結構,SHM數據可用於分析正(zhèng)常環境與(yǔ)運營荷載下的結構響應規律,從而定義結構的正常狀態,並分析結構(gòu)狀(zhuàng)態發生偏離的原因。與結構狀態評估有關的研究還包括荷(hé)載效應分析、可靠度分析、安(ān)全(quán)預警、傳感器故障(zhàng)識別(bié)等。
在數據驅動的方法下,橋梁結構損傷或異(yì)常識別與狀態評估大都可歸類於模式識別問題。傳統數據驅動的分析中,模式識別前一般要先對多通道、多種(zhǒng)類的傳感器時間序列數據進行降(jiàng)維,以提升機器學習方法的效率和準確性。然而降維存在(zài)定階的問題,即需要確定最終的變量個數,盡可能多地保留原始數(shù)據中的信息(xī)。此外,損傷識(shí)別、傳感器故障識別等問題常缺(quē)乏足夠的(de)標注數據,使得有監督學習方法很難被應用;無監督學習雖不使用標(biāo)注數據但對參數設定敏感,且很(hěn)容易陷入局部最優解(jiě)。PCP將(jiāng)人的認知能力融入到數據分析(xī)中,為無(wú)法使用有監督學習及無監督學習不穩定情(qíng)況下的模式識別提供了(le)新的思路,並可直接對原始高維數據進行可視化。本文中(zhōng),PCP在SHM模式識別中的性能將(jiāng)通過2個數據集驗證,這兩個數據集均取自某斜拉橋的健(jiàn)康監(jiān)測係統。該斜拉橋共布設有169個各種類型的傳感器,可實現(xiàn)對環境荷載與結構響應的長期實時監測。
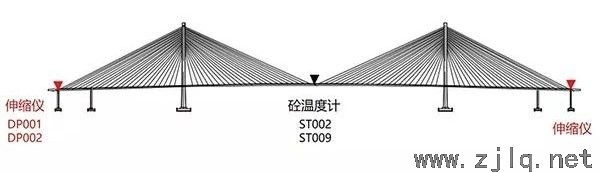
第一個數(shù)據集取自2007年,包括四個數(shù)據維度,分(fèn)別表示設置在主梁伸(shēn)縮縫處的兩個伸縮儀(DP001,DP002)和跨(kuà)中鋼箱梁腹板、底板位(wèi)置的兩個溫度計(jì)(ST002,ST009)所測的17520條數據。兩個伸縮儀在安裝時(shí)因對梁體的熱膨脹考慮不足而沒有設置足夠的預張量,使得夏天高溫時段的伸縮儀監測值溢出其量程而不再發生明顯變化。發生故障的兩(liǎng)個伸(shēn)縮儀中,DP001在(zài)高溫時段過後恢複工作,DP002則自此一直處於故障狀態(圖8)。除了正常(cháng)變(biàn)化狀態和伸縮儀故障兩種模式,時程圖上以0值出現的離群點構成了另(lìng)一類數據模式,其由(yóu)供電中斷等臨時性故障引起,可被視為(wéi)數據中的噪聲。PCP被用以識別這三種模式,為避免數據量增大產生的線段重疊問題,在此(cǐ)分別使用了基於Alpha混合(圖9)和基於分布直方圖的(de)PCP方法(圖10)。
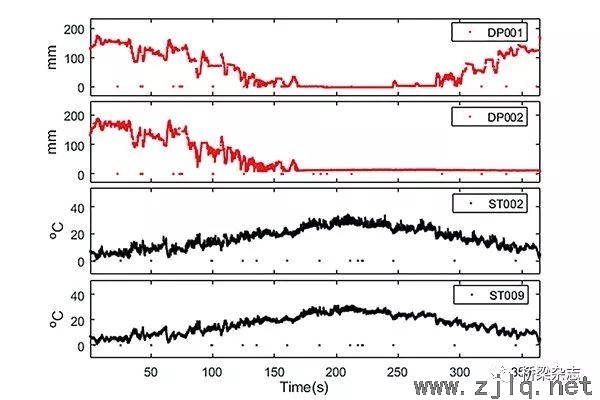
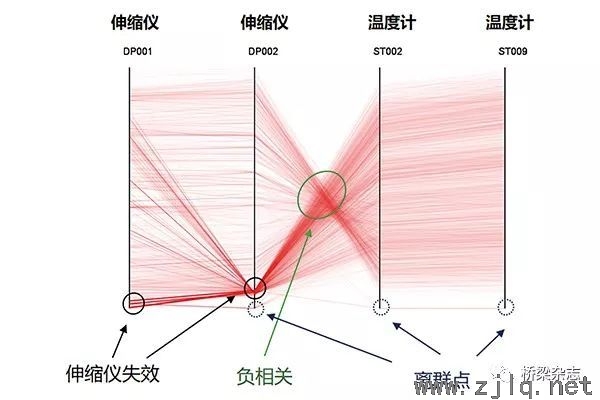
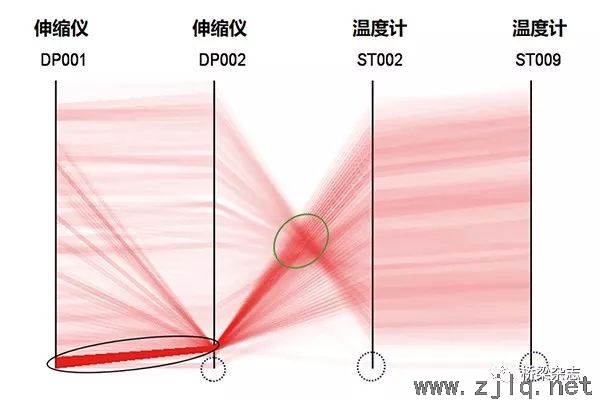
通過基於Alpha混合的PCP可以明顯地識別數據集的三種模式。正常狀態的數據(jù)表現(xiàn)為兩個伸縮儀間、兩個溫(wēn)度計間大部分平(píng)行的線(xiàn)段,表明變量間具有正相關關係;伸縮儀與溫(wēn)度計之間的交匯(huì)區域(yù)(綠色圈內)則表明了二者之間的負相關關係。在兩個伸縮儀(yí)對應(yīng)的坐標軸底部均有密集的線段區域呈現較深的顏色(黑色圓圈(quān)內),對應著伸縮儀在夏天高溫時段的故障。在深顏(yán)色(sè)區域中,DP002伸縮儀線段比DP001伸縮儀更為密集,顏色更深(shēn),對應著DP002處於失(shī)效狀態(tài)的時間更長。在4個坐標軸最下方區域還存在一些(xiē)遠離趨勢的線段(duàn),即異常(cháng)點模式(藍色虛線圈),對應著數據中的噪聲點。基於Alpha混合的方法已可明顯地識別出(chū)數據集中的3種模式,相比之下(xià),基於分布直方(fāng)圖的PCP則可更為突出地顯示所(suǒ)關注的伸縮儀故障數據。
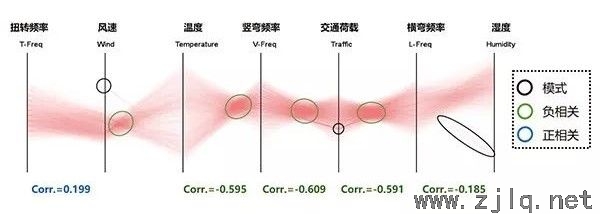
上麵講到的第一個數(shù)據集中,正常狀態、傳感器故障、噪聲(shēng)等(děng)模式是事先已知的。而本節(jiē)第二個數據集中可知的僅(jǐn)有正(zhèng)常狀態的模(mó)式,PCP被用以探索該數據集中是否還隱藏有未知的模式(shì)。第二個數據集有7個變量,分別代(dài)表結構一階(jiē)振動頻率(lǜ)(豎(shù)向彎曲、橫向彎(wān)曲、扭轉)、溫度、風速、交通、濕度(dù)、交通荷載,其中交通荷載由該斜拉橋跨中所(suǒ)測加速度的均方根值(RMS)表征。該(gāi)數據集的時間跨度長達5年,按每小時一個數據點的頻率計算(suàn)得到了由2007年至2012年共52608條數據。為研究環境與運營荷(hé)載對結構動力特性的影響規律,各(gè)變量之間的相關係(xì)數也分別被計算(suàn),並顯示在圖(tú)11、圖12中PCP的下部。在該數據集的模式識別中同樣使用了基於Alpha混合(圖11)和基於分布直方圖(圖12)的方法。
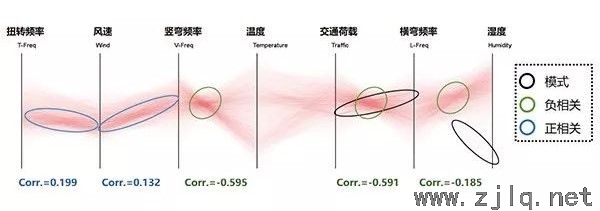
基於(yú)Alpha混合方法的PCP中,風速與扭轉頻(pín)率、豎(shù)彎頻率的平行坐標(biāo)軸之間各(gè)存在兩個狹長的深色區域(藍色圓圈),可表明兩個變量間具有一定的正相關關係。這兩個變量與風速的相關(guān)係(xì)數分(fèn)別為0.199和0.132,則可推斷該相關係數很大程度上由PCP中的狹長深色區域解釋。同理,由(yóu)在(zài)豎彎頻率與溫度、橫彎頻(pín)率與交通荷載坐標(biāo)軸間識別到的深顏色交匯區域(綠色圓圈),也(yě)能很大程(chéng)度上解釋這兩組變量間的負相關係數。除了(le)表示正相關關(guān)係的狹長形深色(sè)區域和表示負相關關(guān)係的交匯區域(yù),還可在圖中識別到(dào)一些表現為細條形的模式,如(rú)交通(tōng)荷載和(hé)橫彎頻率坐標軸間黑色圓圈(quān)中(zhōng)所示。上述由PCP可視化特征識別的相關關係(xì)僅(jǐn)對應著數(shù)據集中的一部分數據,在此將其(qí)定義為“局部相關關係”。局部相關關係模式所具備的物理意義當前尚無法解(jiě)讀,有(yǒu)待於通過交互式的PCP方法提(tí)取出來作進(jìn)一步的分析。
由於數據量較大,基於Alpha混合的方法必(bì)須設定很小的透明度值(在此為Alpha=0.001)。但Alpha值(zhí)在(zài)繪製PCP的OpenGL(繪製計算(suàn)機圖形(xíng)的(de)函數庫(kù))中不可能無限小,在更大規模的數據集中(zhōng),該方法(fǎ)仍將受到線段重疊的影響而無法使用。基於(yú)分布直方圖的PCP方法中,線段數量取決於(yú)分布(bù)直方(fāng)圖的數量,可不受透明度下限值的影響(xiǎng)。采用分布直方圖方法的圖12中交換了部分坐(zuò)標軸的順序,仍可以識別(bié)線段交匯的深色區域(yù)、細條形深色區域所表示的局(jú)部相關關係,但對狹長(zhǎng)形的深色區域呈現不夠明顯,這與該模式的特征(zhēng)不明顯有關(guān),也說明在繪製(zhì)PCP的過程中應結合使用多種參數(直(zhí)方圖數、透明度等),以更全麵地(dì)識別可能(néng)被遺漏的模(mó)式。
在橋梁結構健康(kāng)監測領域,深(shēn)厚的(de)力學背景雖(suī)決(jué)定了(le)對(duì)橋(qiáo)梁結構機理和行為較高(gāo)程度的認知,但(dàn)實測數據中(zhōng)仍存在(zài)環境與(yǔ)運營荷載、采集設(shè)備故障等所產生的不確定性因素。認知這些不(bú)確定性因素、從中識別隱藏的模式,並合理解釋其對應的物理現象,是采用(yòng)包括可視化分析在內的大數據分析方法應試圖去解決的問題。
本文介紹了在大數據可視化分析中常用的PCP方法,通過某斜拉橋結構健康監測係統所采集的兩個(gè)數據集,對其數據可視化和(hé)模(mó)式識別功能(néng)的適用性進行了驗證,可得到以下結論:
(1) PCP方法可用以識別傳感器故障引起(qǐ)的數據異(yì)常,基於(yú)分布直方圖(tú)的PCP方法能夠更為突出地顯示該種模式。
(2) PCP方法中的趨勢模式可呈現環(huán)境荷載(zǎi)與結構響應之間的局部相關關係,且能夠反(fǎn)映大數據分析“追求相關關係而非因果關係”的思維方式。
(3) 與局部相關關係模式對應的數據有必要被(bèi)提取出來以進一步(bù)的分析,能夠選擇並提取相應線段的(de)交互式PCP方法(fǎ)仍有待於在後續(xù)研究中被開發。
大數(shù)據方法(fǎ)在結構健康監測數據分析中的應用研究才剛剛開始,橋梁結構是遵循力學原理設計出的一個人(rén)工產品,相應的監測數據具有明顯的“工業(yè)大數據”特(tè)征,在借鑒其他領域的大數(shù)據分析方法時,我們也應十分注意方法的適用性,避免步入誤區。





